Building a Query Service
Background
This is a blog post I wrote back in Seekret before it was acquired by DataDog and never got published.
The Seekret product has a few basic logical entities that represent how we see the API world. The most central logical entity is API Endpoint - holding information about a request/response tuple like host, service, path, method, and schema.
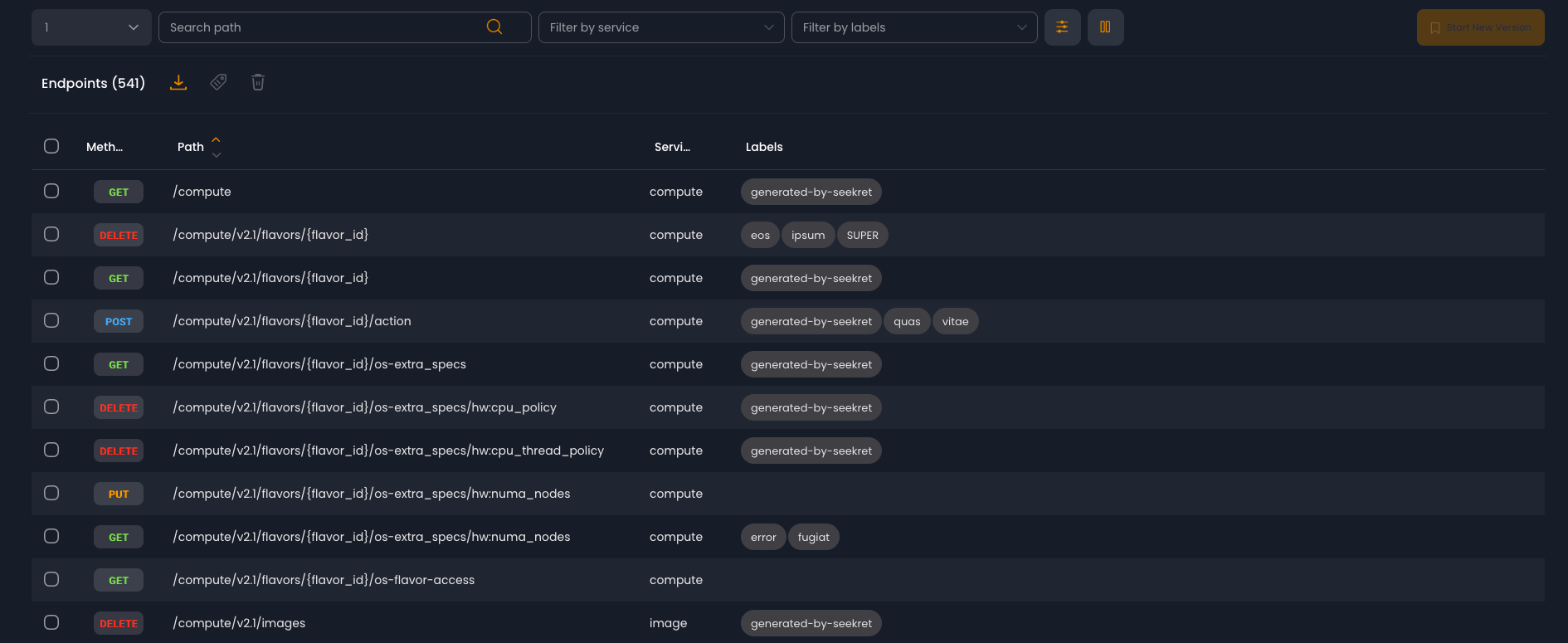
A list of endpoints in the “old” Seekret dashboard
As the product grew our users wanted to filter their endpoints by more and more fields. Our filtering was based on the Material UI Grid component which executes user queries in-memory on the browser. Due to that we could only filter by fields that were displayed in the table. For example consumer names or parameter names were out of scope because they are not displayed to the user in the main table. This lead us to plan a new query “system”, implemented as a backend service allowing us to filter by any field no matter what is displayed in the table.
This sounds promising but it was not simple. Firstly, our deployment architecture is heavily micro-service based where each micro-service is responsible for a specific domain, causing data to be spread across multiple services. Furthermore an endpoint is a central concept in our system, thus it is no surprise endpoint data is spread across many micro-services. This ruled out many simple possibilities and forced us to look at the big picture.
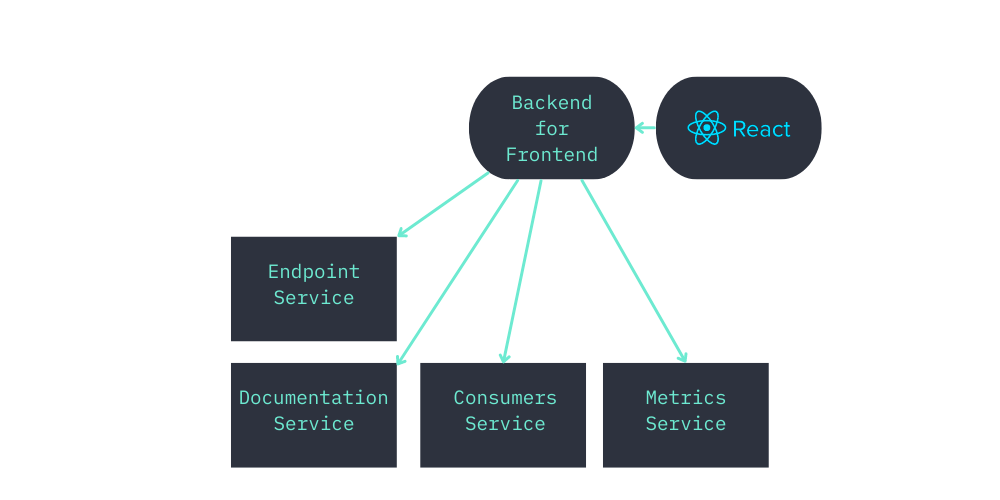
Seekret deployment architecture focused on different services related to the endpoint structure
Focus Areas
When revamping our endpoint query we wanted to focus these areas
Federated Search
In our micro-service deployment many endpoint fields are scattered in different services, this meant we must implement an aggregation logic which is many times referred to as “Federated Search”. We must support querying all fields of an endpoint no matter where they are stored or what service owns that information.
Nested Objects
On top of normal endpoint queries (eg find all endpoints where path is /health), We also must support querying the schema of endpoint request or response. This can be a powerful when writing queries, allowing users find endpoints based specific fields in the response, their format and so on.
The following query (in some pseudo query language) demonstrates the power of this tool. We can now write a query to find all endpoints that have a parameter that is labeled as AUTH but is not documented as required. If you are the developer responsible for this service, this hints you have an authentication feature that can be bypassed.

find endpoints that are AUTH but are not required (in a pseudo query language)

find endpoints that are labeled AUTH but are not required
To make this query possible we need to be able to query the endpoints schema, including all the parameters in the request , and no matter what solution we selected it would have forced us to preprocess our data to make writing this query simple (long story short this is because our internal data structure is recursive).
Avoid Data Duplication
We preferred to avoid data duplication if possible, and we know that avoiding data duplication should not always be the goal, there is an interesting discussion about this topic here: Microservices without data duplication . In our case data duplication would be implemented by copying endpoint data from all micro-services to a new single database. In addition we would need to delete all endpoint data from our copy table that no longer exists in the main micro-services and propagate all modifications that were made to existing endpoints into our copy table. This process seemed fragile so we decided that if we can avoid it, it would be best.
Minimize Coupling
We want to minimize the coupling between query logic and the existing micro-services, this might be a obvious but we still need to have it in the back of our mind to avoid choosing solutions that are easy in the short term but will hurt us in the long term. If we don’t make sure to decouple the implementation, changes to many services will require to change the query service as well, slowing down our development velocity.
Solutions
It is always better to buy an existing solution than to create one from scratch, so we carried on and started researching existing solutions. If you are interested in doing research of your own I suggest reading this excellent post 0x002 - Search as a Service. For me, a major discovery was the differences between search and query.
Search VS Query
During my work, I found out there is a difference between the concepts of query and search. A query is done using DQL (database query language) while a search is done using IR (information retrieval query language). This boils down to the different value each language provides.
According to Wikipedia
Broadly, query languages can be classified according to whether they are database query languages or information retrieval query languages. The difference is that a database query language attempts to give factual answers to factual questions, while an information retrieval query language attempts to find documents containing information that is relevant to an area of inquiry.
In other words, a query must provide a factual answer; it must be repeatable, comprehensive, and deterministic. On the other hand, a search should provide results that are relevant to the user query and even return result one might not expect to receive if they are relevant.
This was significant for us. Comparing Algolia and their competitors using these lenses we can easily see they have a big focus on search while we need a strong and easy query solution.
Available Solutions
Long story short, this is how we evaluated the possible solutions. Some are better at some things and others are better at others, if you have a different deployment architecture or preferences you might find that one of these solutions fits you perfectly.
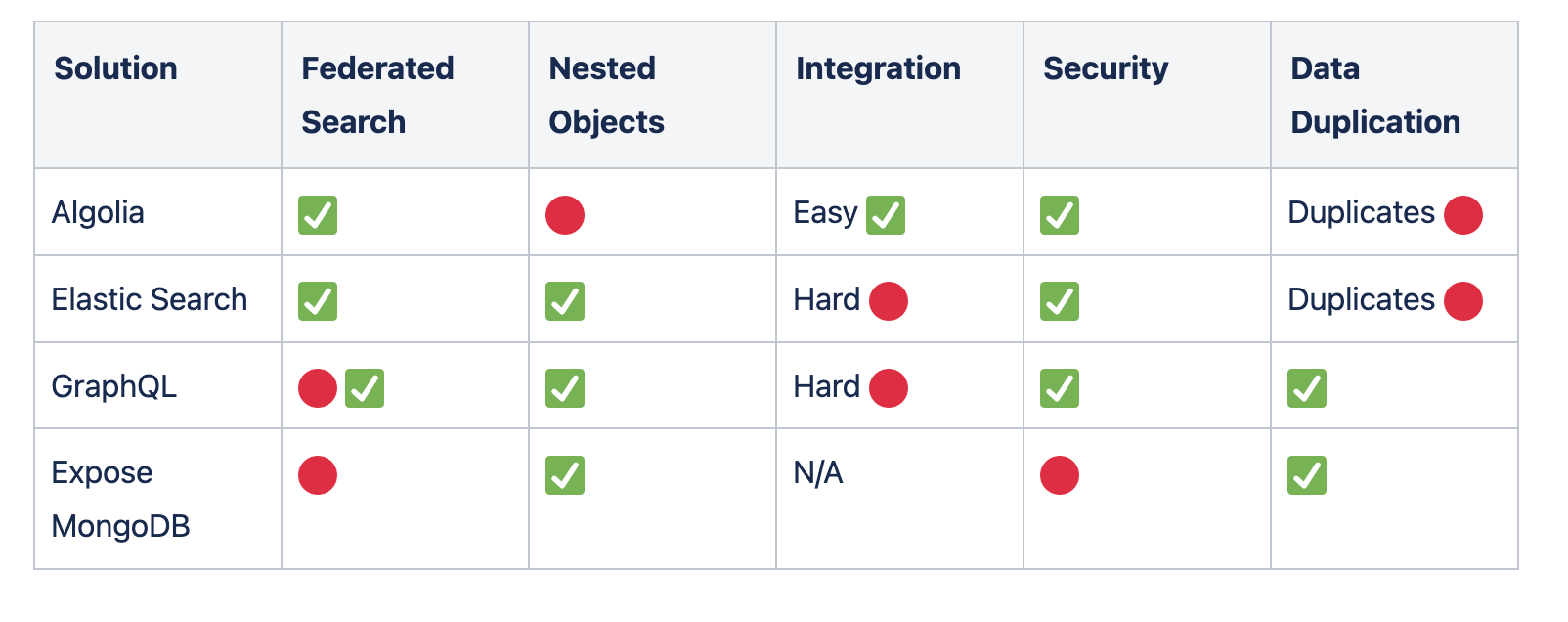
Algolia - Search as a Service
Algolia empowers Builders with the Search and Recommendation services they need to build world-class experiences. Integration was super easy for me, furthermore I could immediately show a UI preview to my colleague and get feedback quickly.
The main blocker we had using them was running queries on Nested Objects. Let’s say I want all to query all endpoints with a parameter labeled AUTH and are required, I would write the query:
endpoint.parameters.label:"AUTH" AND endpoint.parameters.required:trueThis is problematic because in case an endpoint has two parameters, one is required and the other one is labeled AUTH our query will return this endpoint while the wanted result would be an empty result.
Elastic Search
Elasticsearch is a free and open-source search engine allowing you to search for nearly any kind of information - including textual, numerical, and geospatial data. Elastic can be self-hosted and there are also cloud providers that provide fully supported Elastic as a service.
From reading blogs and documentation elastic search seems to be much more complicated than Algolia, it seemed to me it would be best if we had a “Query” team to maintain this service over time, the cost of such team seemed irrelevant at the point. Furthermore Elastic requires implementing an ETL pipeline. This is especially complicated in our case as we expected endpoints to change all the time. As endpoints are added, removed and modified frequently, streaming these changes to the new query service would be clumsy and fragile (read more why we prefer not to duplicate data).
If you still want to use Elastic for your search service I would recommend reading this guide, it seems pretty detailed and friendly How to use Elasticsearch to Create an Exceptional User Experience in Retail
GraphQL
GraphQL is an open-source data query and manipulation language for APIs, and a runtime for fulfilling queries with existing data. Endpoints in GraphQL are made out of many resolvers, each developed manually and usually backed by a specific query to a database (eg: SELECT ... WHERE ... IN queries) or a fetch from a micro-services (eg: resolver who calls GET endpoint-service.local/endpoints)
On one hand, this is a good fit for our need for decoupling the query service from internal micro-services databases by relying only on exported APIs. On the flip side, it is impossible to offload the filtering to the database, filtering jobs will be done naively after running all joins in memory.
On top of that, aggregating data from multiple resolvers is done by the GraphQL infrastructure making it hard to optimize it. The implementer of a GraphQL resolver doesn’t know what fields the query will request or in what order it will request the resources, forcing GraphQL to implement joining multiple resolver outputs in a naive way (compared to what possible if I had just implemented a plain Golang function)
This made me think I might be better off implementing a fetch function that collects data from all services just as GraphQL would do but without the fancy features of such as “Ask exactly for what you need“ field selection or the awesome developer tools GraphQL provides.
On top of that, implementing generic database-like filtering in GraphQL is considered a questionable practice, and in my opinion, would be complicated for our product users to write.
Expose MongoDB database
We considered exposing our database with a read-only user, this approach is taken by some major tech companies such as Stack Overflow. You can use their great data explorer How many upvotes do I have for each tag? - Stack Exchange Data Explorer, it is even opensource so you can fork it StackExchange/StackExchange.DataExplorer
Even though some had successfully used this method, for us exposing a database as a query service had some disadvantages:
- If we make a configuration mistake, we might be exposed to an attack allowing data theft. We don’t have developer attention for this overtime.
- Our data is federated between multiple services, forcing us to copy data from micro-services to a central database. Not a deal breaker but as we said we would prefer to avoid this.
- Our current data structure is not built with search in mind, even if we hadn’t had the two issues above, we would still need to preprocess our data before storing in the database.
Our Solution
Finally, we decided to implement a query service. It accepts queries in the JMESPath language. We wanted to de-couple the query service as much as possible and the most effective way we found was to make the query service use only exported API of our internal services (no direct database access and no “infrastructure” code to be inserted in key services)
Query Service public API (protobuf)
message QueryRequest {
string query = 1;
}
message QueryResult {
google.protobuf.Value result = 1;
}Notice how the result is a generic interface with a generic return value, this is equivalent to a JSON object. This is on purpose to align with the JMESPath specification, which allows defining and changing the shape of the returned data. This will allow us to provide an "Advanced Query" window in our product without forcing a specific shape for the query results.
Query service is responsible to fetch all data relevant to the current user, and only then applying filters to it using JMESPath. Note this is still better than GraphQL as we can implement an aggregation logic that is tailored for our internal implementation. We chose to do this because:
- Simplest implementation possible, but keeps spaces for us to optimize it down the road
- Avoid edge-cases of “ghost data” that exists in the query-service index but was deleted from the main database
- Minimize coupling of our existing services to the new query service
One thing we had to take into consideration against this solution is query speed, to reduce this issue we decided query service will cache results to avoid network latency as much as possible. The cache will have an inactivity mechanism deleting cache entries that were not active in the past seconds/minutes. We will trigger a cache load when the user interacts with the query input and delete it after the user has stopped interacting with it for a significant amount of time.
Additional benefits of choosing this solution are decoupling of the query language. JMESPath was chosen as a language that is not tied to a specific database implementation allowing us to change the implementation without changing the query service interface.
Further more, in a security perspective query service holds only a copy of real data in memory, so in case of a security issue no real data can be deleted.
Final Result
Note: this wasn't used much in production as the company was acquired by DataDog right after this deployment, who knows maybe implementing a query service can get your copany acquired too haha
hope you enjoyed this post :)